鎌形 稔 4月/ 7/ 2019 | 1
目次
概要
開発したスクレイピングツールで色々なサイトのデータを抽出を実際に行い、ツールの精度を高めていこうかと思います。実際に使ってみないと色々な状況に適したものは作れないので。
また、抽出するだけでは面白くないので、抽出したデータを集計、分析してみようかと思います。
開発当初よりテスト対象として使用させてもらっていたキネマ旬報社が提供する映画鑑賞記録サービスの kinenote を今回データ抽出してみます。
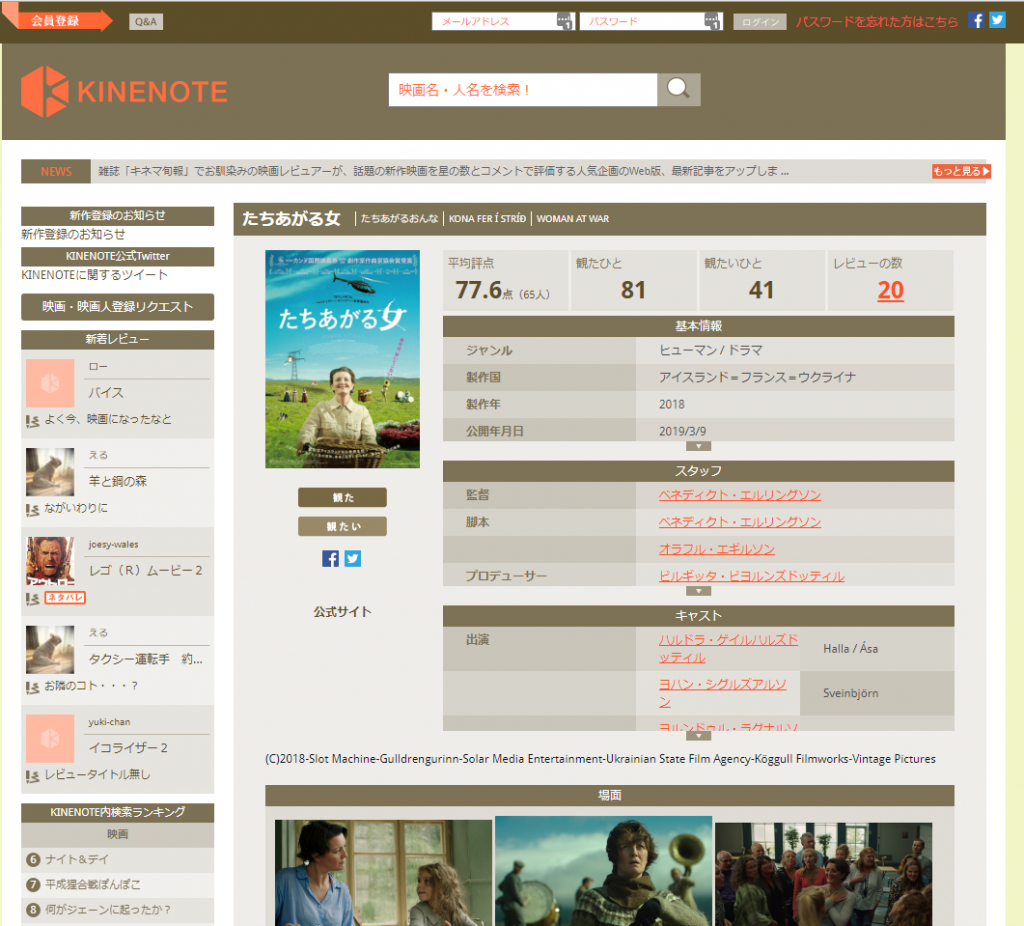
データ取得方針
kinenoteは基本的に映画のレビューを複数ユーザーで登録、共有していくサービスです。
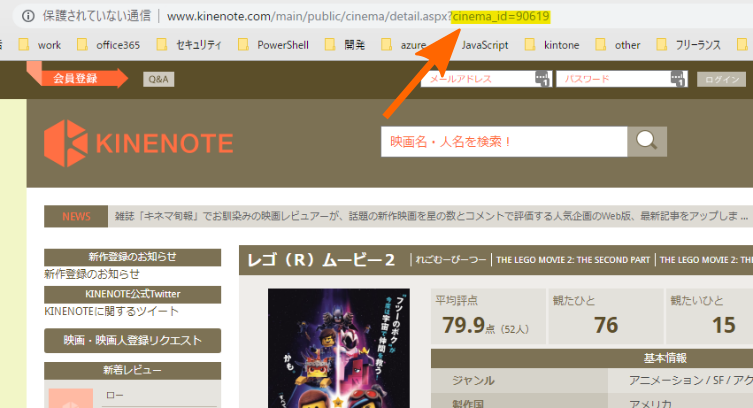
そのため映画の基本情報が元データとなり、その下にユーザーレビューデータが紐づいているようです。それぞれの映画タイトルは「cinema_id」という数字のみの形式のIDが振られています。
「cinema_id」をインクリメントしながら順次抽出していけば良さそうです。
取得項目
今回は、映画の基本情報を抽出し、集計していこうかと思います。取得項目は以下のようになります。
| 項目名 | 備考 |
| タイトル | |
| ジャンル | |
| 製作国 | |
| 製作年 | |
| 監督 | 複数ある場合でも1名のみ取得 |
| 脚本 | 複数ある場合でも1名のみ取得 |
| 出演者 | 3名のみ取得 |
| あらすじ |
以下は取得項目の入れ物とHTMLの取得部分。CSSセレクターはChromeの開発者ツールで解析してくれたやつをコピペしただけです。
const KinenoteScraping = function(logger){
this.buffer = {
title : "", // タイトル
genre : "", // ジャンル
productionCountry : "", // 製作国
productionYear : "", // 製作年
director : "", // 監督
screenplay : "", // 脚本
performer1 : "", // 出演者1
performer2 : "", // 出演者2
performer3 : "", // 出演者3
overview : "", // あらすじ
};
this.log = logger;
};
KinenoteScraping.prototype.do = function(htmldoc, url, cinemaid){
this.log.debug("スクレイピング処理開始");
if(htmldoc.$('h1').text() === ""){
return Promise.reject("HTTP Get Error!!");
}
this.buffer['title'] = htmldoc.$('h1').text().trim();
this.buffer['genre'] = htmldoc.$('#movie > div.movie_info > div.block_info > div.block_right > div:nth-child(3) > div > div > table > tbody > tr:nth-child(1) > td').text().trim();
this.buffer['productionCountry'] = htmldoc.$('#movie > div.movie_info > div.block_info > div.block_right > div:nth-child(3) > div > div > table > tbody > tr:nth-child(2) > td').text().trim();
this.buffer['productionYear'] = htmldoc.$('#movie > div.movie_info > div.block_info > div.block_right > div:nth-child(3) > div > div > table > tbody > tr:nth-child(3) > td').text().trim();
this.buffer['director'] = htmldoc.$('#movie > div.movie_info > div.block_info > div.block_right > div:nth-child(5) > div > div > table > tbody > tr:nth-child(1) > td').text().trim();
this.buffer['screenplay'] = htmldoc.$('#movie > div.movie_info > div.block_info > div.block_right > div:nth-child(5) > div > div > table > tbody > tr:nth-child(2) > td').text().trim();
this.buffer['performer1'] = htmldoc.$('#movie > div.movie_info > div.block_info > div.block_right > div:nth-child(7) > div > div > table > tbody > tr:nth-child(1) > td.setWidth').text().trim();
this.buffer['performer2'] = htmldoc.$('#movie > div.movie_info > div.block_info > div.block_right > div:nth-child(7) > div > div > table > tbody > tr:nth-child(2) > td.setWidth').text().trim();
this.buffer['performer3'] = htmldoc.$('#movie > div.movie_info > div.block_info > div.block_right > div:nth-child(7) > div > div > table > tbody > tr:nth-child(3) > td.setWidth').text().trim();
var tmpText = htmldoc.$('#movie > div.movie_info > h2:nth-child(3)').text().trim();
if(tmpText === "場面"){
this.buffer['overview'] = htmldoc.$('#movie > div.movie_info > div:nth-child(10)').text().trim();
}else{
this.buffer['overview'] = htmldoc.$('#movie > div.movie_info > div:nth-child(5)').text().trim();
}
return Promise.resolve(this.buffer);
};
module.exports = KinenoteScraping;
保存形式
スクレイピングツールは、CSV、TSV、JSONファイルに保存かMongoDBに保存できます。
今回は集計作業をやりやすくするためMongoDBを選択しますが、実行スピードの計測等もしたいので、別途CSVファイルに保存するケースも実行してみたいと思います。
実行方法
ツールでは、大量のHTTPリクエストを発行するので、シリアル(直列)実行かパラレル(並行)実行かを選択できます。
実行スピード計測のため、こちらもシリアルとパラレル両方実行してみたいと思います。
パラレルは同実行数10で試します。
また、1回のリクエストが終了した後、インターバルに2秒の休憩時間を入れます。息継ぎ時間を入れておかないと、向こうのシステムに迷惑が掛かるので。
また、実行スピード計測は全件対象すると大変なので、(どうやら kinenote の登録データは9万件以上あるようです。 )1000件指定とします。
スピード計測方法は以下のようなログの実行時間をあとから集計する形をとります。
[2019-04-02T02:51:48.393] [DEBUG] 2d975e906eb2554c92d48d939e9e7011 – kinenoteデータスクレイピング処理開始
[2019-04-02T02:51:48.405] [DEBUG] 2d975e906eb2554c92d48d939e9e7011 – Paramaters: CinemaId 1
集計にはPowerShellでも良かったのですが、Node.jsで一応以下のように書きました。
最終的にオブジェクトをコンソール出力していますが、PowerShellでCSV形式にして集計する予定です。(ちょっとそこまでNode.jsでやるのが面倒でした。)
PowerShellはコマンド一発でCSV出力できるのが魅力的です。
const fs = require('fs');
var readline = require("readline");
var filePath = process.argv[2];
const LogBuffer = function(logMsg){
this.log = [logMsg];
}
LogBuffer.prototype.getLog = function(){
return this.log.sort((aa, bb) => {
return aa.time.getTime() - bb.time.getTime();
});
};
LogBuffer.prototype.getTimeDiff = function(){
var tmpArray = this.getLog();
return tmpArray[tmpArray.length - 1].time.getTime() - tmpArray[0].time.getTime();
};
var logRecord = new Map();
var stream = fs.createReadStream(filePath, "utf8");
var reader = readline.createInterface({ input: stream });
reader.on("line", (data) => {
if(data.match(/interval/) !== null){
return;
}
var dataArray = data.split(" ");
var hashKey1 = dataArray[2];
var logObj = {
"time" : new Date(dataArray[0].replace(/[\[\]]/g,"")),
"type" : dataArray[1].replace(/[\[\]]/g,""),
"message" : dataArray.splice(4).join(" ")
};
if(logRecord.has(hashKey1)){
logRecord.get(hashKey1).log.push(logObj);
}else{
logRecord.set(hashKey1, new LogBuffer(logObj));
}
});
reader.on('close', function () {
for(var key of logRecord.keys()){
var logs = logRecord.get(key).getLog();
var record = {
hashid: key,
cinemaId: logs[1].message.split(" ")[2],
startTime: logs[0].time.toLocaleTimeString(),
endTime: logs[logs.length - 1].time.toLocaleTimeString(),
timeDiff: logRecord.get(key).getTimeDiff() / 1000
}
console.log(JSON.stringify(record));
}
});
ログ集計コマンド
上記スクリプトを以下のように実行してCSVファイルを作成、Excel集計します。
node .\LogParse.js .\parallel_mongodb_WebScraping.log | ConvertFrom-Json | Export-Csv -Path .\parallel_mongodb_WebScraping.csv -NoTypeInformation
実行時間計測結果(1000件)
| 実行方法 | 保存形式 | トータル実行時間 | 1リクエストの平均実行時間(秒) |
|---|---|---|---|
| 直列 | CSV | 1:02:30 | 1.7 |
| 直列 | MongoDB | 1:23:17 | 3.0 |
| 並列(同時実行10) | CSV | 0:31:05 | 9.2 |
| 並列(同時実行10) | MongoDB | 0:33:13 | 10.3 |
トータルの実行時間を見ると、1000件の処理を直列して実行するより10件づつ並列実行する方がやはり早く完了しています。
保存形式で言うと、CSVファイルよりMongoDBに保存した方が若干遅くなるというのは、DBとのやり取りが必要な分遅れが出ているものと思います。
また、1リクエストの平均実行時間で言うと直列より並列の方が遅くなるのはNode.jsがシングルスレッドで処理するからでしょうか?並列で実行しても結局処理の待ち合わせ時間が発生して遅くなっているという事でしょうか?
全件集計に向けて
今のところCSVファイル保存で並列実行するのが早いのは分かっています。
しかし、それでも9万件オーバーの処理だと単純計算で45時間位掛かってしまう事に。。。
同時実行数をさらに上げて試すというのもありですが、時間の短縮にはスクリプトのロジック再検討が必要かもしれません。
その辺はまた次回に。
ブロトピ:今日のブログ更新
ブロトピ:ブログ更新通知をどうぞ!
ブロトピ:ブログ更新通知
ブロトピ:ブログ更新しました!