鎌形 稔 4月/ 15/ 2019 | 1


![]()
目次
前回までの話
映画レビューWebサービスのkinenoteのデータを当方で開発したスクレイピングツールを使って実際にデータ抽出してみました。
ツールで真っ正直に直列処理するとCSV保存の場合でもMongoDB保存の場合でも 、
1000件の映画情報をスクレイピングすると約1時間オーバー。
Promise.allで同時並行10件(※)の処理ではCSV保存、MongoDB保存共に 約30分でした。
詳細はこちらに。
(※前回、詳細なロジックを記載してませんでしがた、並行実行はPromise.allで実行しています。また、前回は並列という言葉を使いましたが、正確には並行が正しいようです。)
kinenoteのデータは全件抽出するとなると9万件オーバーなので、並行実行でも単純計算すると45時間掛かる?!ゆえに、【出来ればもう少し】スピードアップを図りたいのです。
データ再検証
ログをもう少し細かく見てみました。
前回は1リクエストの開始から終了までのトータル時間のみ集計しましたが、今度は①スクレイピング処理時間、②外部出力処理時間の二つに分けて集計してみました。
以下がその表です。

並行実行だと1リクエスト平均10秒位かかってるのですが、その処理の大部分はスクレイピング部分で時間を食っているのが分かります。
なんとなく外部出力(I/O)処理で時間掛かってるのかと思ってたのですが逆でした。
この傾向は直列処理時も同様なので、スクレイピング処理部分がネックなのは確かなようです。
まぁ、http通信してるのでレスポンス待ちで時間掛かってると言われれば、なんとなく納得してしまいそうですが。。。。
でも、並行実行した時と直列実行した時で平均処理時間がこんなに変わる原因って何ですかね?
Node.jsの並行処理
自分なりに調べてみました。
今回のツールではPromise#all()による並行処理を行っています。
並行処理って、処理が「同時進行」で別々に処理されるイメージを勝手に持っていたのですが、そうではなく、処理としては同時に走らせるのですが、それぞれの処理を細かく区切ってちょっとづつ切り替えながら実行していく形なんですね。ある瞬間で見ると、今まさに実行されている処理は一つしかなくて、あたかも同時に実行してるように見えるだけなんです。
なぜそんな動作かというと、Node.js、JavaScriptはシングルスレッドで動作しているからこうなるようです。
まったく別々に同時進行していくのは「並列処理」というもの。 当初私がイメージしていたのはこちらでした。ある瞬間の実行されている処理が複数ある形です。
これはマルチスレッドで実行可能な動きになるようです。
参考にさせてもらったサイトはこちら。
直列、並行と並列の処理の違いは以下のような認識です。
手書きで申し訳ありません。誤字、脱字が目立ちますが。。。
シーケンスが一筆書きなのが直列と並行。完全に二手に分かれるのが並列。
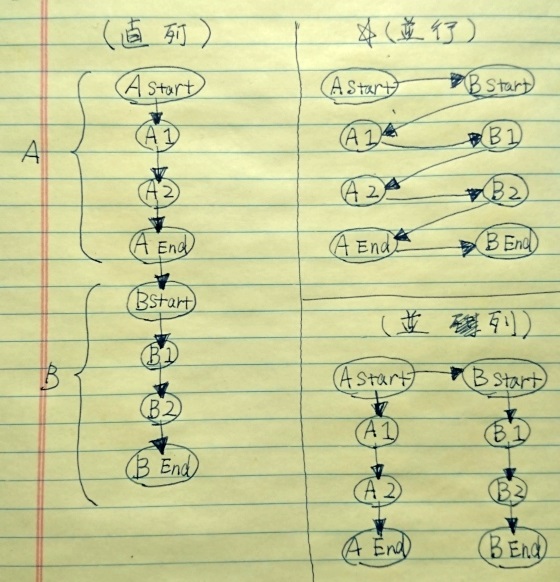
並行実行で10プロセス起動して処理してましたが、1~10のプロセスのうち1のプロセスを実行中は2~10の処理は動かないわけで。そして、その実行中のプロセスが重かった場合、その待ち時間が同時に他のプロセスの待ち時間に加算されていくので、ある意味並行実行するプロセスが多ければ多いほど、後続プロセスの待ち時間は加算されていくのだと思います。
という事で、私のなかでの結論としては、WebWorker等の並列処理を実装しないかぎりは処理のスピードアップは望めないのだろうという事になりました。
並行実行プロセス数を調節してみる
恐らく多ければ多いほど平均の処理時間は多くなっていくものと思います。
トータルの処理時間としては、どうなるのか?変わらない気がしますが。。。
試してみましょう。
並行実行数20で処理
当初10でやってたので倍にした形です。平均処理時間も倍になるでしょうか?

1リクエスト終了までの平均実行時間がほぼ倍になりました。予想通りになりました。
しかし、全リクエスト終了までのトータル実行時間が2分程短縮されました。
何だこれ?っと思いましたが、よく考えたら1ループ(並行実行)が終わる度にインターバルタイムを2秒設けていたことが原因でした。
並行実行10から20に倍にした事でループ階数が減り、その分インターバルタイムが減ったため、終わるまでのトータル実行時間が2分程減ったというわけです。
というわけで、インターバルを2秒から1秒とかにして、さらに同時並行30位にすればまた少しスピードアップしそうです。
というか、以下である事が分かります。

つまり、Node.jsがシングルスレッドで並行処理している限り、1000回のリクエスト処理時間のトータルとしては変わらない。その際に1回のループにセットしたインターバルタイムの秒数分変化があるだけ。と分かりました。
並行実行してインターバル回数が減ればその分だけ、時間削減してるだけという。。。
じゃぁ、何の為の並行実行なんだという感じがしますが、今回のツールのロジックにはそぐわないのかもしれません。
スピードアップするため、その他の可能性を探る
とりあえず、WebWorkerの並列処理というのは有りますが、まずは現状のロジックで何かできないか探ります。
その後、単純なマシンパワーを上げていく力技を試してみようかと。現状、ローカルPCで実行してるのですが、AzureかAWSでCPUをちょっと多く積んだ実行環境を作って試そうかと思います。
その辺はまた次回に。
全データ抽出はもう少し先になりそうです。。。
ブロトピ:今日のブログ更新
ブロトピ:ブログ更新通知をどうぞ!
ブロトピ:ブログ更新通知
ブロトピ:ブログ更新しました!